


Votre partenaire premium
pour l’externalisation
du traitement de vos données
Votre partenaire premium
pour l’externalisation
du traitement de vos données



Accueil

Nous vous accompagnons dans l’annotation de vos images, vidéos et nuages de points afin de constituer des datasets structurés, prêts à entraîner ou évaluer la performance de vos modèles de computer vision.
Classification, keypoints, bounding boxes 2D, polygones ou segmentation : nos équipes traitent chaque projet sur mesure, selon vos
spécifications techniques.

Notre objectif est de constituer un dataset diversifié, complet, équilibré et représentatif des scénarios que vous souhaitez modéliser, afin d’optimiser les performances de vos modèles et de réduire les coûts d’annotation.
Grâce à notre expertise, nous assurons une préparation de données fiable, cohérente et adaptée aux exigences de vos projets d’intelligence artificielle, de machine learning ou de traitement automatique du langage.

Nous structurons et enrichissons vos données textuelles pour entraîner ou évaluer vos modèles d’intelligence artificielle.
Nos équipes annotent une large variété de documents : comptes rendus médicaux, rapports techniques, publications scientifiques, contrats,
documents administratifs ou transcriptions.

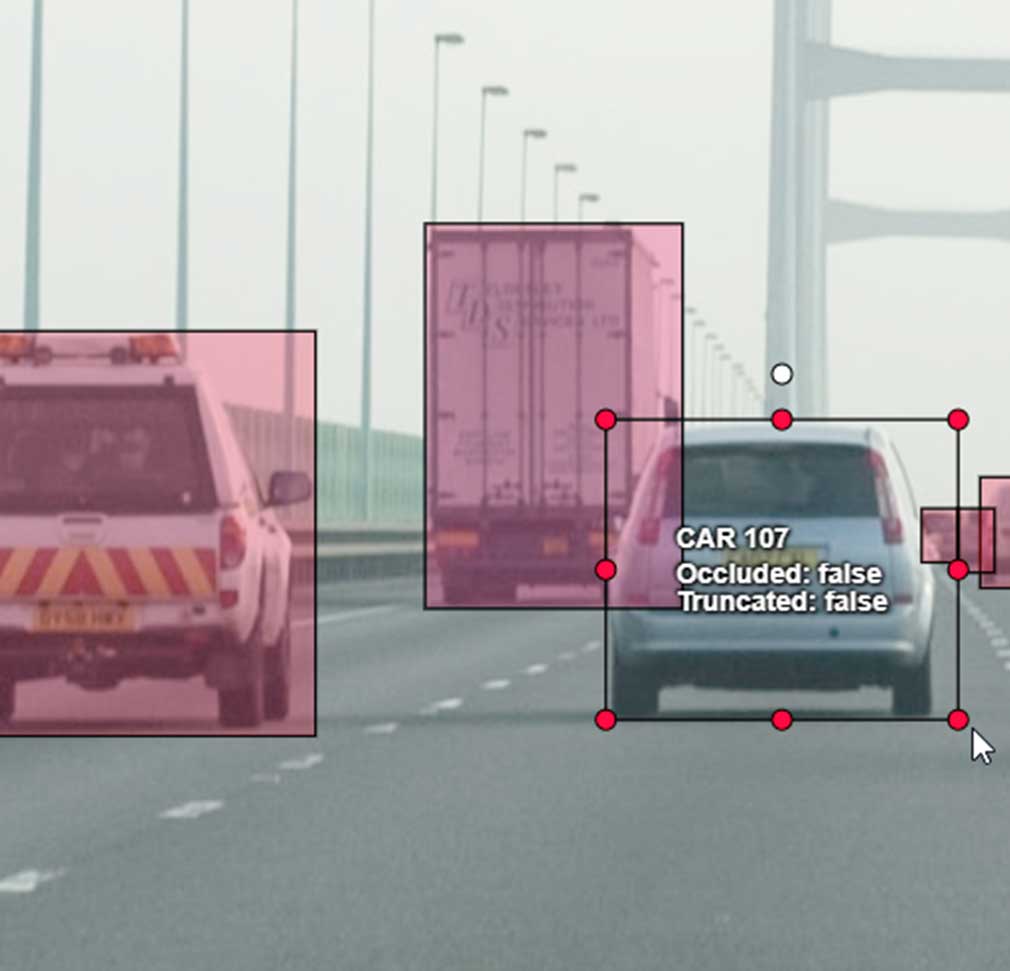
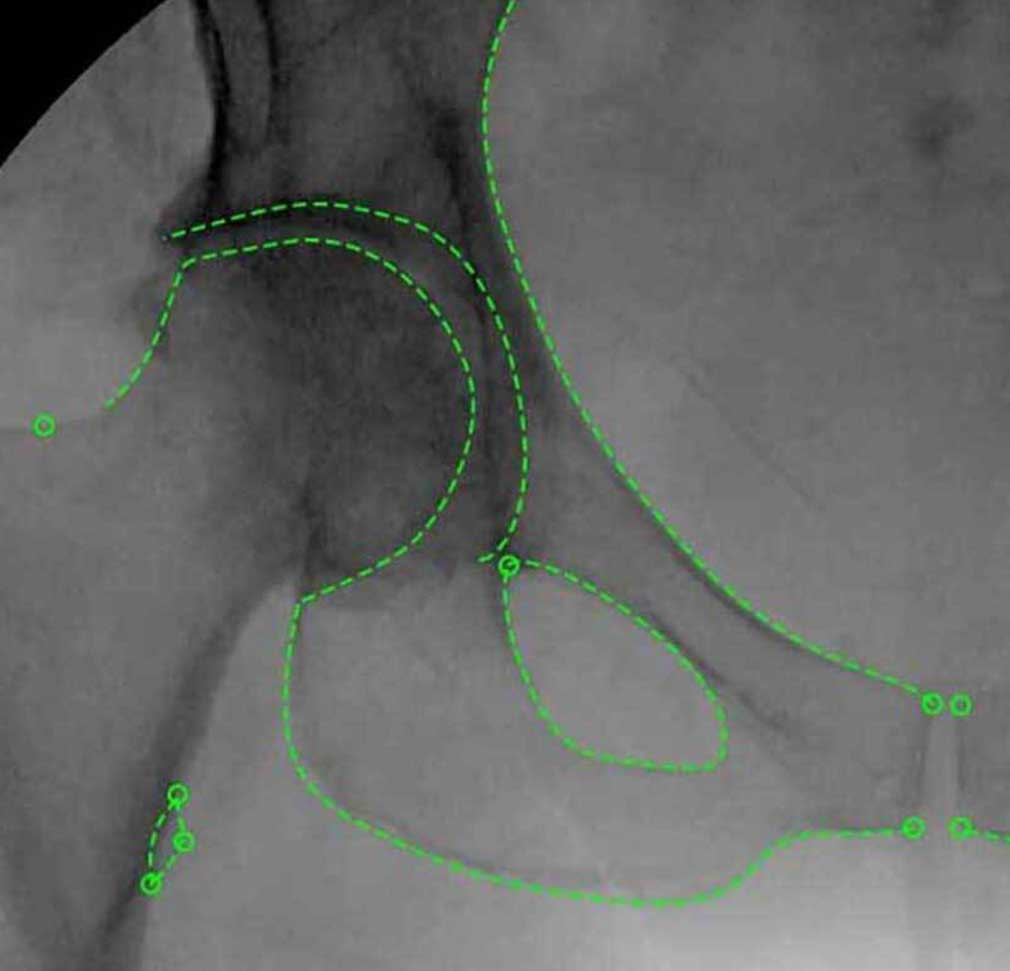



- Classification d’image
- Boîte englobante (BoundingBoxes 2D, 3D)
- Segmentation par polygone
- Segmentation par masque (sémantique, instance, panoptique)
- Keypoint et Skeleton (connexions entre keypoints)
- Tracking des objets
- Segmentation 3D
- Association des objets en 2D et 3D (projection d’images et nuages de points)
- Annotation de nuages de points
- Détection, correction et suppression des erreurs, doublons ou incohérences
- Harmonisation des formats, ontologies et schémas de labellisation
- Extraction et structuration de métadonnées
- Assurer la cohérence et la compatibilité de jeux de données provenant de sources différentes pour produire un dataset unique, propre et exploitable.
- Segmentation, filtrage et équilibrage statistique des jeux de données
- Contrôle qualité continu et gestion versionnée des datasets
- Annotation sémantique
- Reconnaissance d’entités nommées (NER)
- Classification de texte
- Analyse de sentiments et d’opinions.
- Extraction de relations
- Annotation syntaxique et morphologique
- Coreference & linking
Secteurs d'activité
Nos solutions sur mesure s’adaptent aux besoins spécifiques de chaque secteur.
Notre savoir-faire s’étend à de nombreux secteurs, chacun avec ses exigences techniques, réglementaires et métier.
Grâce à nos équipes spécialisées et à notre méthodologie rigoureuse, nous créons des datasets fiables, cohérents et adaptés aux besoins de chaque application IA.
Automobile
Annotation et segmentation de données destinées aux véhicules autonomes, aux systèmes d’aide à la conduite, à l’analyse de flux routiers, à la détection du marquage au sol et des panneaux de signalisation, et à l’inspection automobile.
Agriculture
Traitement et annotation d’images issues de capteurs ou prétraitées par des modèles d’IA, avec contrôle humain, correction des faux positifs et prise en compte des éléments non détectés, pour la surveillance des cultures, la détection de maladies et de mauvaises herbes, et l’optimisation des rendements.
Défense & sécurité
Solutions sécurisées d’analyse d’images et de vidéos sensibles, mises en oeuvre sur les environnements des clients, permettant l’identification et la classification d’objets alliés et ennemis selon des ontologies à haut niveau de granularité couvrant terrestre, maritime et aérien, à partir de données issues de capteurs multi-spectraux RGB, IR et SWIR embarqués
Médical
Annotation d’images et de vidéos médicales pour la détection de pathologies, la reconnaissance d’organes et de structures développement de modèles d’IA diagnostique, sur des données issues d’IRM, de radiographies, d’échographies et de chirurgies laparoscopiques, en collaboration étroite avec une équipe de médecins intégrée à nos équipes
Retail & e-commerce
Annotation et structuration de données visuelles pour la segmentation et l’indexation de produits, l’analyse des comportements ou en ligne, et l’optimisation de la gestion des stocks, à partir d’images produits et de flux vidéo.
Smart City
Annotation d’images, de vidéos et de données multi-capteurs pour la détection, le tracking et l’analyse des flux urbains douces), ainsi que pour l’aide à la planification et à l’optimisation des infrastructures urbaines.
Géospatial
Annotation, segmentation et enrichissement de données géospatiales pour des modèles d’IA capables d’analyser le ou stratégique, incluant la détection d’objets civils et d’infrastructures militaires, l’identification de changements (panneaux piscines, installations spécifiques) et l’anticipation des évolutions territoriales.
Industrie & logistique
Annotation d’images et de vidéos pour la détection de défauts et d’anomalies, le suivi d’objets critiques et l’analyse de Applications couvrant le contrôle de lignes d’assemblage, la surveillance de procédés et de la sécurité, ainsi que l’assistance autonomes en entrepôt.
Ce que nous faisons
Nous transformons vos données brutes en inputs fiables grâce à l’expertise humaine
Chez Infoscribe, nous transformons vos données en un véritable levier de performance. Alliant expertise humaine, innovation et technologies avancées, nous garantissons une précision sans compromis pour créer des ensembles d’entraînement fiables, puissants et durables au service de vos modèles d’IA.

Organisée pour traiter rapidement de importants volumes de données, notre équipe d’annotateurs s’adapte à vos contraintes de temps, absorbe les pics d’activité et fait évoluer la capacité de production au rythme de la croissance de vos besoins de labellisation.

Un chef de projet dédié Francophone et anglophone, disponible Pour échanger avec vous au cours de visio-conférences. Votre interlocuteur unique, vous accompagne de l’estimation initiale à la livraison finale, il coordonne l’ensemble des échanges et vous tient informé grâce à des comptes rendus réguliers en temps réel à chaque étape importante du projet.

Selon la technicité du projet, nous faisons intervenir des experts métiers (scientifiques, médicaux, agronomes, juridiques, etc.) afin de garantir que chaque annotation est correctement interprétée, nommée et cohérente sur l’ensemble du dataset.
Cybersécurité & protection des données
Infoscribe.ai assure la protection des données grâce à des environnements cloisonnés, des transferts chiffrés, la conformité au RGPD et une sensibilisation continue du personnel. Notre dispositif de sécurité repose sur la certification ISO 27001, un hébergement HDS lorsque requis, ainsi que la réalisation de tests de pénétration annuels afin de prévenir et détecter les risques de cyberattaques
Options Qualité & Processus de Contrôle
Grâce à une méthodologie rigoureuse, et différentes couches de contrôle qualité successives, nous pouvons nous engager sur des annotations avec des niveaux de qualité allant de 95 à 99%
Tarification sur-mesure, adaptée à vos projets
Chaque projet étant unique, nous adaptons notre tarification : à l’heure, à l’image ou à l’objet, après étude de cadence, définition d’un taux horaire et calcul de prix unitaires optimisés
65
290
480
Pour démarrer un pilote
ou échanger sur votre projet
Témoignages et références clients









FAQ
Questions fréquentes
La mise en route d’un projet d’annotation 2D ou 3D lié à des applications de Deep learning nécessite une organisation précise, une réactivité forte et une compréhension immédiate des objectifs du client. Chez Infoscribe, nous avons structuré nos processus pour garantir un démarrage extrêmement rapide tout en assurant un niveau de qualité compatible avec les exigences des pipelines de Deep learning modernes.
Concrètement, nous sommes en mesure de lancer un pilote en moins de 48 heures après validation du périmètre. Ce délai court s’explique par notre capacité à mobiliser rapidement une équipe formée, capable de comprendre les contraintes spécifiques de vos modèles de Deep learning : architecture utilisée, formats de données, besoin en granularité des annotations ou encore risques de biais dans le dataset.
Durant ces 48 heures, nous gérons l’ensemble des étapes critiques : onboarding des annotateurs, formation détaillée aux guidelines, configuration de la plateforme d’annotation, intégration des flux de travail et préparation des procédures de contrôle qualité. Cette préparation accélérée est essentielle pour fournir des données directement exploitables dans vos cycles d’entraînement en Deep learning, qu’il s’agisse de modèles 2D convolutionnels, de réseaux 3D type PointNet ou de pipelines multitâches.
Pour les projets plus larges, dépassant le cadre d’un pilote, le délai moyen de mise en route oscille généralement entre 48 heures et 5 jours ouvrés. Ce temps permet d’affiner les ontologies, d’ajuster les exemples d’annotation à la nature des tâches de Deep learning, et de garantir que la cohérence inter-annotateurs est optimale avant la montée en charge. Nous savons que la qualité des annotations influence directement la performance, la robustesse et la capacité de généralisation des modèles de Deep learning, c’est pourquoi nous accordons une attention particulière à la précision initiale du workflow.
Une fois le projet lancé, nos équipes restent disponibles pour ajuster en continu les processus, en fonction des retours de vos premiers entraînements de Deep learning. Ce dialogue constant nous permet d’optimiser la structure des données, de réduire les ambiguïtés dans les labels et d’améliorer progressivement la pertinence du dataset. L’objectif est clair : garantir que chaque lot de données fourni contribue réellement à augmenter l’efficacité et la stabilité de vos modèles de Deep learning en production.
Grâce à cette combinaison de rapidité, de rigueur méthodologique et d’expertise appliquée au Deep learning, nous assurons une mise en route fluide, sécurisée et parfaitement adaptée aux impératifs de vos projets IA.
.
Les modèles de tarification présentés reposent sur une structure simple, modulable et adaptée à la nature du projet d’annotation. La première approche s’appuie sur une facturation au temps passé, selon une grille évolutive en fonction du volume d’heures commandé : plus le nombre d’heures augmente, plus le coût horaire est ajusté à la baisse.Cette structure s’applique à différents types de prestations, qu’il s’agisse de classification, de délimitation en 2D, de segmentation ou d’annotation de nuages de points.
La seconde approche repose sur une facturation à l’unité. Dans ce modèle, Infoscribe détermine un coût par image ou par objet annoté. Le calcul repose sur une analyse des temps nécessaires, une estimation du rythme d’annotation et une conversion de ces éléments en un coût unitaire. Un projet comportant plusieurs millions d’images peut être évalué à partir du temps total requis.
Enfin, la tarification peut également être ajustée selon la complexité des tâches, les exigences de contrôle qualité ou le niveau d’accompagnement souhaité. Chaque projet fait l’objet d’une étude préalable permettant d’adapter précisément le modèle retenu.
Infoscribe propose une structure flexible associant facturation horaire, facturation à l’unité et ajustements sur mesure, afin de répondre efficacement à la diversité des besoins en annotation.
Infoscribe a conçu son organisation pour répondre efficacement aux besoins des projets de deep learning à grande échelle. Grâce à une équipe de plus de 300 annotateurs francophones, l’entreprise peut mobiliser rapidement des ressources humaines en cas de montée en charge.
Quand le volume de données augmente fortement — que ce soit des images, des vidéos, ou des nuages de points 3D — Infoscribe s’adapte en combinant flexibilité, montée en effectifs et un workflow robuste d’annotation.
En pratique, les processus internes assurent que les données sont préparées, validées et annotées selon des standards compatibles avec les besoins des modèles de deep learning.
L’approche « human-in-the-loop » combine la précision humaine et l’efficacité des systèmes d’IA / Deep AI : cela permet de valider ou corriger les prédictions automatiques, ce qui réduit les erreurs tout en accélérant le rythme de production — un atout clé lorsque le volume explose.
De plus, Infoscribe met en place un contrôle de qualité systématique, avec des relectures internes, des rapports de conformité, et des corrections en boucle si nécessaire, afin de garantir la cohérence des annotations — indispensable pour entraîner des modèles de deep learning robustes.
En cas de gros volumes, l’architecture de production d’Infoscribe — combinant plusieurs filiales, une répartition des tâches, et des chefs de projet dédiés — lui permet de scaler sans sacrifier la qualité. Ce dimensionnement agile aide vos projets d’IA / Deep AI à rester performant même dans des contextes exigeants.
Ainsi, Infoscribe offre une scalabilité opérationnelle et humaine, en garantissant des annotations fiables et reproductibles, parfaitement adaptées aux contraintes des développements en deep learning.
Oui, Infoscribe propose une offre d’essai sous forme de POC permettant de tester ses workflows d’annotation avant tout engagement long terme. Cette approche est particulièrement utile pour les entreprises souhaitant valider la qualité du traitement de données, la rigueur méthodologique et la compatibilité du pipeline avec leurs propres modèles de deep learning.
Le POC permet de reproduire, à petite échelle, l’ensemble du cycle de traitement de données : réception du corpus, définition des guidelines, configuration des outils, annotation par nos équipes expertes, contrôle qualité multicouche et restitution des livrables. Cette phase pilote donne une vision précise du temps de traitement, de la précision obtenue et du niveau de cohérence attendu sur un projet large. Elle constitue également une occasion idéale pour mesurer la valeur ajoutée de nos méthodes sur vos projets de deep learning.
Durant le POC, les équipes Infoscribe analysent les besoins spécifiques de votre cas d’usage : granulométrie des labels, structure des ontologies, formats d’export, mais aussi contraintes particulières liées à votre pipeline de deep learning. Cette période permet de personnaliser le traitement de données selon vos objectifs, qu’il s’agisse d’annotation 2D, 3D, vidéo, suivi d’objets ou segmentation complexe.
Le POC sert également à valider notre capacité à monter en charge. Vous pouvez ainsi évaluer comment nos équipes gèrent le traitement de données à grande échelle, comment elles maintiennent la cohérence des annotations et comment elles ajustent les process pour garantir un dataset parfaitement exploitable dans un environnement de deep learning.
À l’issue du POC, vous recevez des livrables complets, accompagnés d’un rapport de performance, d’une estimation fiable des coûts et d’une projection réaliste des délais pour un déploiement élargi. Cela vous permet de valider objectivement l’efficacité de notre traitement de données avant d’envisager un engagement sur la durée.
Ainsi, l’offre d’essai Infoscribe constitue une étape rassurante et transparente pour confirmer l’adéquation de nos workflows avec vos besoins en deep learning.